Опубликовано в журнале Новый Берег, номер 44, 2014
Русские переводы Шекспира далеки от оригинала. Чтобы проиллюстрировать это, я однажды взял один из сонетов Бродского из «Двадцати сонетов к Марии Стюарт» и представил, что было бы, если бы Маршак перевел этот сонет:
Это сонет Бродского:
Красавица, которую я позже
любил сильней, чем Босуэла — ты,
с тобой имела общие черты
(шепчу автоматически «о, Боже»,
их вспоминая) внешние. Мы тоже
счастливой не составили четы.
Она ушла куда-то в макинтоше.
Во избежанье роковой черты,
я пересек другую — горизонта,
чье лезвие, Мари, острей ножа.
Над этой вещью голову держа,
не кислорода ради, но азота,
бурлящего в раздувшемся зобу,
гортань… того… благодарит судьбу.
А так выглядел бы этот сонет Бродского в переводе Маршака:
Сколь ни был Босвел по сердцу тебе,
Но страсть моя к другой была сильнее.
Ты обликом отчасти схожа с нею —
Мне вспомнилось в приглушенной божбе.
Нас было вместе не свести судьбе…
Уйти в плаще за счастием, вернее,
За грань — ты не позволила себе.
Я грань иную пересек позднее:
Земля в ней встретит неба синеву,
А острота ее клинку подобна.
На ней вздымаю гордую главу
Не для дыханья. И пускай утробно
Пузырится азот по железам,
Но горло благодарно небесам.
Это наглядная иллюстрация и полезный стилистический экзерсис. При этом возникает естественный вопрос: как отличить один литературный стиль от другого? Можно размахивать руками и рассуждать о нюансах, можно камлать и призывать духи давно умерших поэтов, но все это будет в значительной степени субъективно.
Я предлагаю вашему вниманию новый научный метод, который позволяет оценивать литературные стили. Для того чтобы воспользоваться этим методом, нам понадобится всего один численный параметр — известность слов. Для каждого слова мы определим этот параметр так: поищем слово в Гугле и посмотрим количество хитов. Количество хитов и будет нашим численным параметром. К примеру, поиск на слово «Shakespeare» даст 32 миллиона хитов, а поиск на слово «Wordsworth» даст 2 миллиона хитов. Мы знаем, что Шекспир известнее Вордсворта. И это знание подтверждается результатами нашего численного метода.
Чтобы проанализировать текст мы рассмотрим семь показателей:
1 — процент слов в тексте, у которых количество хитов меньше 10 милионов;
2 — процент слов в тексте, у которых количество хитов от 10 до 20 миллионов;
3 — процент слов в тексте, у которых количество хитов от 20 до 40 миллионов;
4 — процент слов в тексте, у которых количество хитов от 40 до 80 миллионов;
5 — процент слов в тексте, у которых количество хитов от 80 до 160 миллионов;
6 — процент слов в тексте, у которых количество хитов от 160 до 320 миллионов;
7 — процент слов в тексте, у которых количество хитов от 320 до 640 миллионов.
Отметим, что в первую категорию попадут редкие слова, в особенности — неологизмы, архаизмы, имена мифологических персонажей и т. п. В целом, чем больше в тексте будет подобных слов, тем более текст будет напыщенным, выспренним, высокопарным. А остальные категории будут характеризовать общий словарный запас, а также сложность и плотность текста. Естественно предположить, что романтические тексты по сравнению с текстами барокко будут иметь больший показатель в первой категории и меньший показатель в остальных.
Для чистоты сравнения мы возьмем произведения одного и того же жанра — сонеты. Барокко будет представлено сонетами Шекспира, обращенными к смуглой леди. Примером романтизма станут сонеты Джона Китса. А образцом викторианской литературы будут «Португальские сонеты» Элизабет Браунинг.
Вот так выглядят семь численных показателей для сонетов различных эпох.
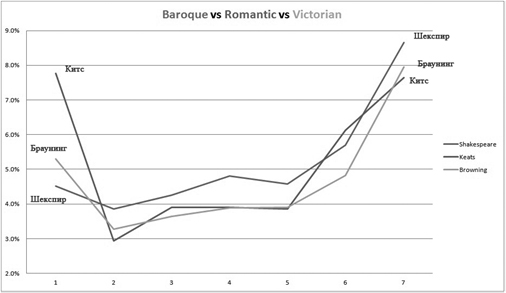
Сравнение семи этих показателей подтверждает нашу гипотезу о различии стилей. Следовательно, этим методом можно эффективно пользоваться для анализа литературных стилей.